Before we enter into a discussion about predictive modeling and its values to the insurance industry, we need first to understand what we mean by it.
In January 2012 the Society of Actuaries published Report of the Society of Actuaries Predictive Modeling Sub Committee, which looked into predictive modeling in life insurance. In this they defined predictive modeling as:
“…a process used in predictive analytics to create a statistical model of future behavior. Predictive analytics is the area of data mining concerned with forecasting probabilities and trends. A predictive model is based on a number of predictors, factors that are likely to influence or predict future behavior. The model output is a set of factors that predict, at some confidence level, the outcome of an event.”
Predictive modeling is not new; it is something we know about from our earliest education, daily life and in our industry right now. Predictive models are really an extension of some of the basic principles we learned at school, and predictive modeling is in essence a guessing game – a very sophisticated and scientifically based guessing game that uses algorithms and models to project an outcome.
Always remember that a model is not perfect; it is only numbers and probabilities. While a model can lead to better solutions for making decisions, or better odds at winning, success models are, by definition, predictions or probabilities about future behaviors. They cannot predict an individual behavior or action; they can only suggest the probability of a particular behavior or action, based on past observations.
Creating a predictive model happens in five stages: thesis, data collection, data study, data validation, and updating of the model.
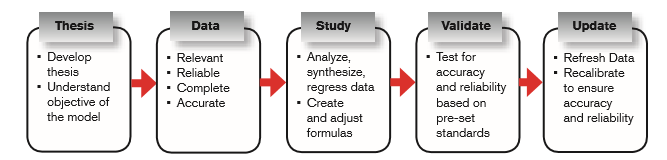
It is essential that the models and underlying data are updated and recalibrated frequently. The frequency required depends on the data and the model. Over time models are accepted (e.g., credit score) or not, but models often must be refined and adjusted before being accepted. Eventually people catch on, thereby turning existing models into the status quo. To keep up and remain relevant and accurate, models must be continually adjusted based on fresh data.
Predictive model hurdles
What are some of the key issues surrounding the use of predictive models in a life underwriting environment?
- Many people simply do not understand or trust the math, and the ‘black box’ syndrome leads to skepticism – particularly when the output is adverse.
Additional information about the impact of the model must be understood by a critical mass before being accepted. In the U.S., the credit score was not understood until its impact was felt (by not getting loans, jobs or competitive interest rates). If we cannot explain the decision the math has made, how will the agent and customer feel?
- The rapidly changing regulatory environment. When can you use data, and will this data be available for continued use?
- Concerns about privacy affect the acceptance of predictive modeling, but these concerns are really about data collection and sourcing. Collecting data and using it for other purposes without complete transparency causes concerns and conflict and raises the regulatory warning flag.
- Models are not perfect; they are merely educated guesses. They can only approximate reality because behavior is subject to change. Data can be biased, incomplete or wrong. Data can also overlap and conflict. In addition, models are software-based and subject to defects.
Why are predictive models so prevalent and becoming popular in all forms of business and leisure activities?
Predictive modeling has been around for a long time, but its use in solving real-world problems has accelerated for several reasons.
There is a wealth of information and data available today due to such factors as the proliferation of Internet use, mobile phone apps, social networking, and the conversion of public records from paper to online databases. In 2011, 1.2 trillion GB of data was uploaded (roughly equivalent to 20,400,000,000,000 music albums’ worth of information).
The combination of the massive amounts of data and the advancement of technologies to obtain, consolidate and quickly analyze the data, as well as the changing backgrounds of the C-suite (increasing numbers of CFOs, chief risk officers, CIOs on executive committees, and the cross-pollination of executives, especially in property and casualty companies where predictive modeling is more common) all contribute to the growing influence of predictive models in business, as companies seek to capitalize on the possibilities afforded by all this data.
Predictive modeling may be more part of our everyday lives than we currently realize. National Australia Bank is well known to use predictive modeling in marketing campaigns and has won multiple awards from the industry and independent analysts.
Where are we going?
We require a new approach to meet full underwriting pricing in order to meet the constant demand of ‘faster, better cheaper.’ The adaptation and use of predictive modeling concepts will contribute greatly to delivery into new, untapped or underserved markets.
Possible areas where predictive modeling can benefit life insurance include purchasing and retention, pricing reserving, claims, fraud and underwriting risk selection.
Underwriting-specific uses include screening, anti-selection, evidence replacement, improving the accuracy of underwriting decisions and increasing the decision-making power of underwriting engines.
In addition to models we can create directly, the accelerated use of predictive models in the field of medicine will positively impact life and living benefits insurance. Examples are Humedica’s modeling of patients at risk from congestive heart failure, and Harvard Medical School’s use of Twitter to model cholera outbreaks.
Conclusion
Adopting predictive modeling capabilities into our practices is critical to our future offerings and key to our ability to thrive in a competitive marketplace. Reinsurers need to focus on how we can add value to our clients and answer the looming question, “How will this technology and information affect our price?”
Here are some final thoughts on predictive modeling:
- Make predictive modeling a high-priority initiative
- Continue current activity and plan for future predictive modeling work
- Add to staff, skills and experience.

