Beneath the surface
Clearly, the impairment analysis has become easier and more efficient with the integration of AI. But, again, we have only begun to explore the possibilities of consolidated and organized data.
Take laboratory data, for example. Given the variety of sources in which lab results are provided – whether from insurance panels, third-party data, electronic health records, or attending physician’s statements, underwriters must often review each independent lab value from its respective source. This process can be cumbersome, requiring underwriters to piece together results to estimate mortality based on recent findings, trends, or averages.
However, with generative AI’s ability to re-structure all lab findings, we can now develop rules- based logic that is more encompassing. The following snapshots illustrate how lab tests can be categorized, filtered, and assessed, regardless of their source.
Exhibit 6: Customized tabular worksheet (CTW)

Exhibit 7: Excel output

Whether using a customized tabular worksheet or a case-specific Excel output, underwriters can now consolidate laboratory findings from all available sources into a streamlined format. This consolidation offers significant opportunities:
- Precise analysis of less common labs – Underwriters can now analyze lab tests that are less common across various sources. For example, NT-proBNP testing is more common on insurance panels, while CBC findings are generally found in medical records or third-party data, as shown in blue on the CTW in Exhibit 6. Previously, this required cross-referencing findings within their respective source documents. By consolidating all laboratory findings and relevant results, regardless of their source text, underwriters are less likely to overlook or dismiss a potentially significant finding worth consideration.
- Simplified trend analysis – Trend analyses, such as the glucose testing shown in the Excel output in Exhibit 7, are now more straightforward. Underwriters can examine all values of a particular test, regardless of its source location. This capability is extremely valuable when tests oftentimes are scattered across larger underwriting files.
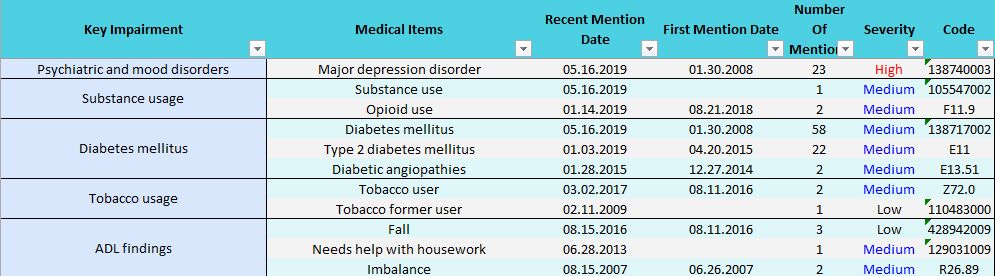
- Reviewing recent findings across requirement – Consolidated outputs allow underwriters to review recent findings from all underwriting requirements simultaneously. The Excel format automatically organizes by date, while the CTW highlights the “recent mention date” (highlighted in orange in Exhibit 6), which addresses the most recent results. This feature applies to medical impairments and diagnostic tests, providing the underwriter a clear, organized view of findings by severity and date.
Furthermore, categorizing these findings by “key impairments,” and associating them with relevant codes, such as the A1c test highlighted in green in Exhibit 6, enhances data consolidation. This enables the development of impairment-specific rules or severity models. With all underwriting data consolidated, underwriters gain the ability to organize relevant information logically, dynamically, and accessibly, unlocking a wealth of possibilities.
In essence, the value of structured data lies in its organization. By presenting information in an intuitive, easy-to-consume format, structured data empowers underwriters to achieve more precise, efficient, and informed decision-making.
Opportunities and expectations
Like PDF summaries, structured data is just a way to present the results of a generative AI model. As such, concerns about accuracy in AI models also apply to the structured data they produce.
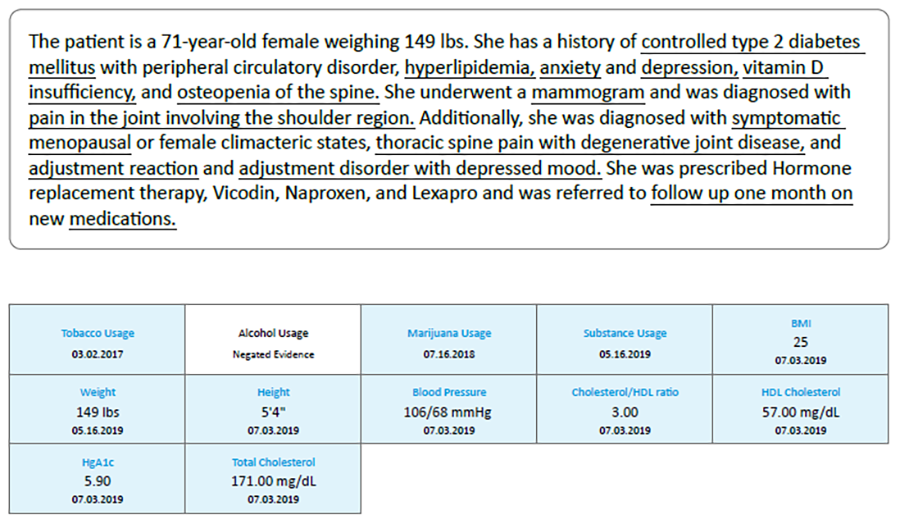
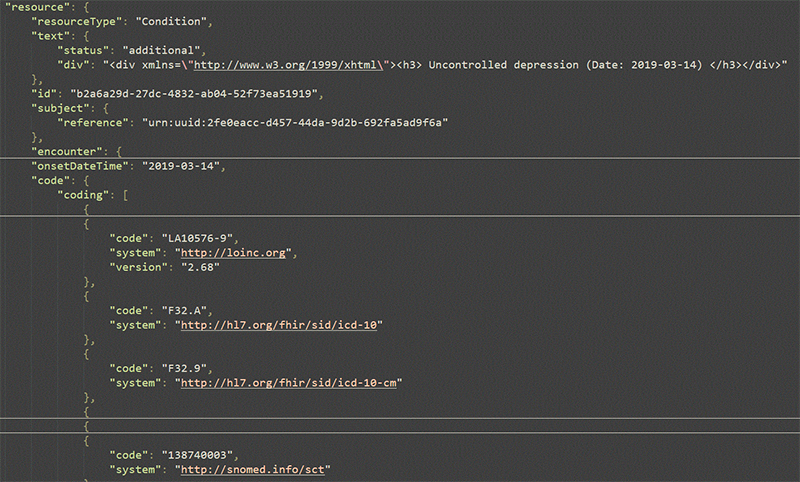
Validating this data is critical. For example, the model may misinterpret or omit medical findings, especially when the input data is complex or unclear. Exhibits 8 and 9 illustrate a case where the model incorrectly identified an individual as having diabetes mellitus. Further investigation revealed that this was simply a diagnosis code used to order glucose testing, and the test result itself was normal. Nevertheless, this erroneous diabetes diagnosis appeared across all structured data formats as well.
Exhibit 8: Chronological overview of conditions or events

Exhibit 9: Hemoglobin A1c result

Exhibit 10 highlights another challenge: A patient’s Crohn’s disease was omitted because the generative AI model was unable to reliably interpret the handwritten details. As a result, all structured data formats failed to mention the patient’s history of Crohn’s disease.
Exhibit 10: Crohn's disease finding
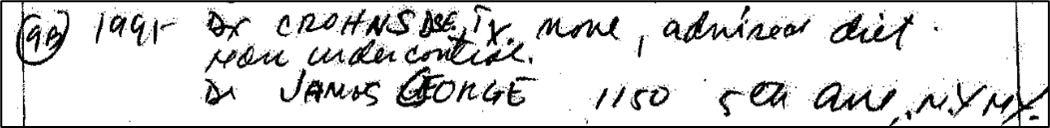
The presentation of medical impairments or diagnostic findings in structured data comes with unique challenges. For instance, while Exhibit 6 highlights the significant benefits of the customized tabular worksheet for data consolidation, there are many instances where fields like “Institution” are left blank. Underwriters must evaluate the relevance and reliability of assessments based on the information source. Further refinement is needed for generative-AI to accurately identify and associate medical findings with their exact sources.
These challenges are due to ongoing efforts to validate structured data based on PDF summaries and an underwriter’s ability to review them. DigitalOwl’s PDF summaries provide hyperlinks to source data, enabling underwriters to verify the legitimacy of the data. This allows underwriters to trace impairments back to their original sources and assess what led to the condition’s “diagnosis,” as seen in the diabetes example in Exhibits 8 and 9.
Consistency and accuracy in structured data are essential – not only for proper risk management in underwriting but also for auditing and claims adjudication.
As generative AI continues to evolve, whether applied to underwriting workflows or case notes, like those from DigitalOwl, the need for improved validation tools and techniques will become critical to advancing structured data analysis and risk assessment.
With continued validation and refinement, the challenges of ensuring accuracy and building confidence in AI-structured data will gradually diminish. Once these hurdles are overcome, opportunities for structured data consolidation and rules development will expand, turning what once seemed a distant future inevitability into a present-day reality filled with possibilities.
And this is only the beginning.
Contact us to learn more about how RGA and DigitalOwl are pioneering AI-enhanced underwriting workflows that drive efficiency and better risk decisions.